声明
此篇文章在字节跳动的技术公众号已经刊登:《字节跳动DanceCC工具链系列之Swift调试性能的优化方案》
原作者是我自己(李卓立 @dreampiggy)而非抄袭,这里在个人博客同时转发一下,去掉了招聘相关文案。不过依旧欢迎大家有兴趣的有志之士加入。
背景
通常来说,大型Swift项目常含有大量混编(Objc/C/C++甚至是Rust)代码,含有超过100个以上的Swift Module,并可能同时包含二进制部分和源码部分。而这种大型项目在目前的Xcode 13体验下非常不好,经常存在类似“断点陷入后变量面板卡顿转菊花”、“显示变量失效”等问题。而且一直存在于多个历史Xcode版本。
图1:Xcode变量区显示卡顿转菊花,测试使用Xcode 13.3和下文提到的复现Demo
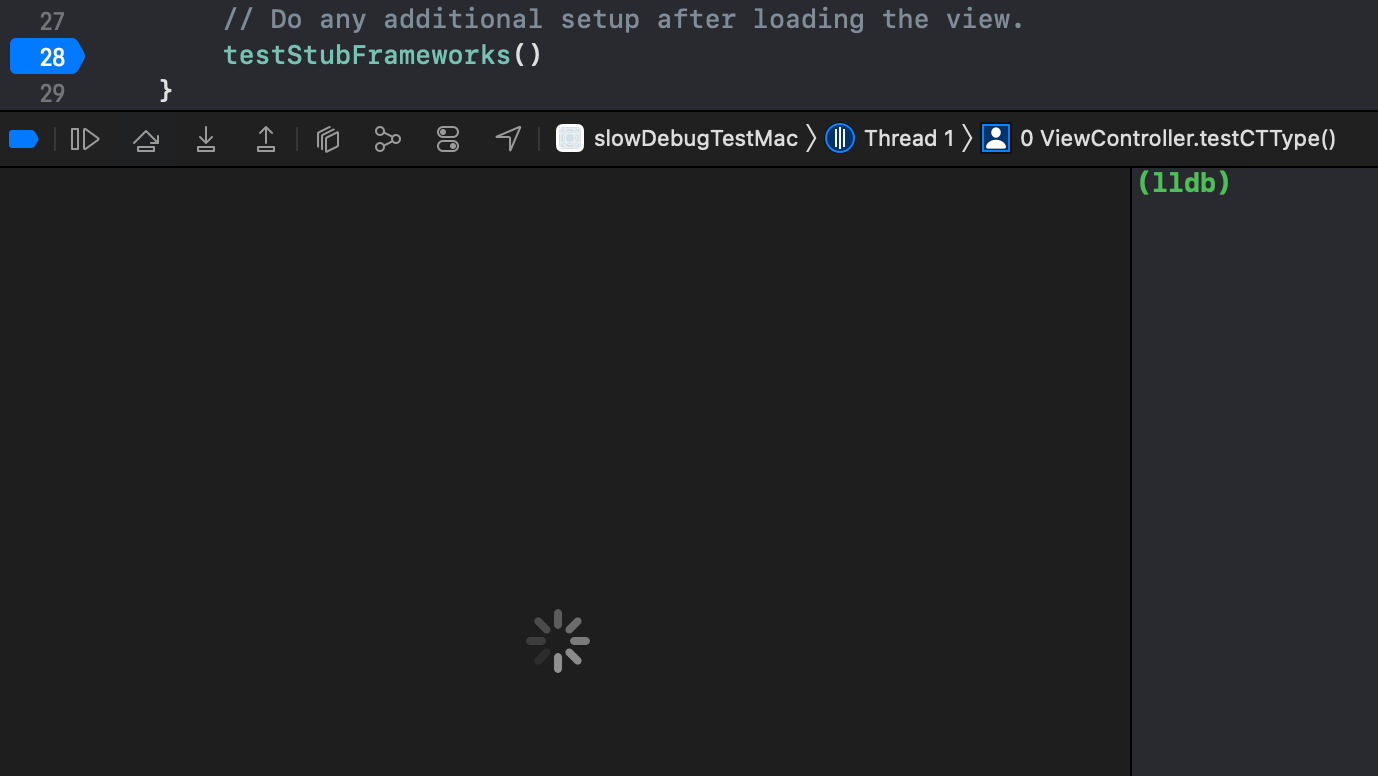
这部分Apple Team迟迟不优化的原因在于,Apple公司的内部项目和外部项目开发模式的巨大差异。Apple内部产品,如系统应用,系统库,会直接内嵌到iOS固件中,并直接受益于dyld shared cache(参考WWDC 2017-App Startup Time: Past, Present, and Future[1])来提升加载速度。这意味着他们通常会将一个App,拆分为一个薄的主二进制,搭载以相当多的动态链接库(Dynamic Framework),以及插件(PlugIn)的模式来进行开发。
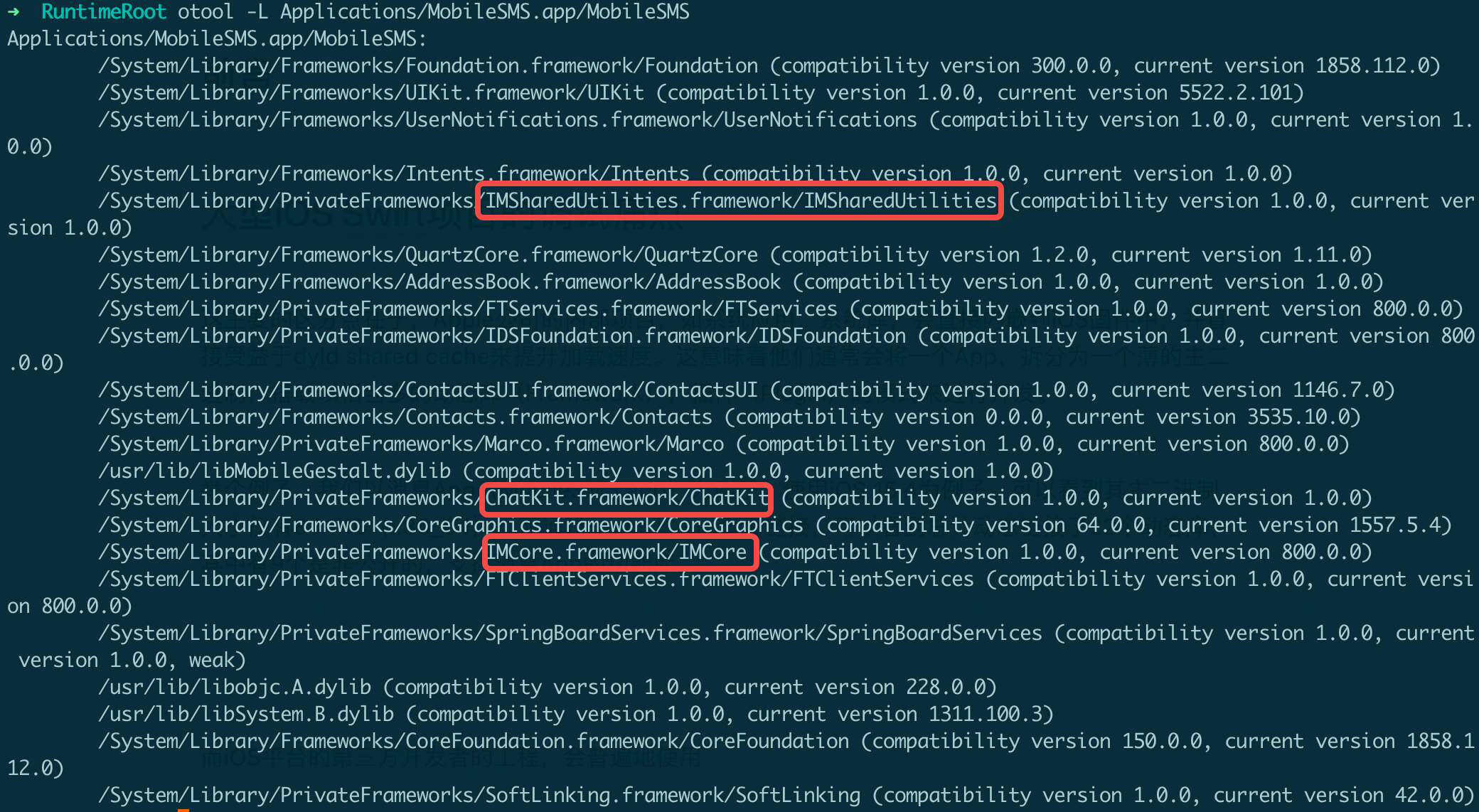
举个例子,我们以iOS的消息App(MobileSMS.app)为例子,使用iOS 15.4模拟器测试。可以看到其主二进制大小仅有844KB(x86_64架构)。通过otool -L查询链接,可以看到总计动态链接了22个动态链接库,其中有9个是非公开的,大都是支撑消息App的功能库,这些库占据了大量存储。
图2:消息App的动态链接库列表
而iOS平台的第三方开发者的工程,为了追求更快的冷启动时长,由于没有了dyld shared cache的优化(dyld 3提出的启动闭包只能优化非冷启动),很多项目会使用尽量少的动态链接库。加之开源社区的CocoaPods,Carthage,SwiftPM等包管理器的盛行导致的Swift Module爆炸增长,预二进制的Framework/XCFramework包装格式的滥用,加之闭源三方公司的SDK的集成,最终形成了一个无论是体积还是符号量都非常巨大的主二进制,以及相当长的Search Paths。
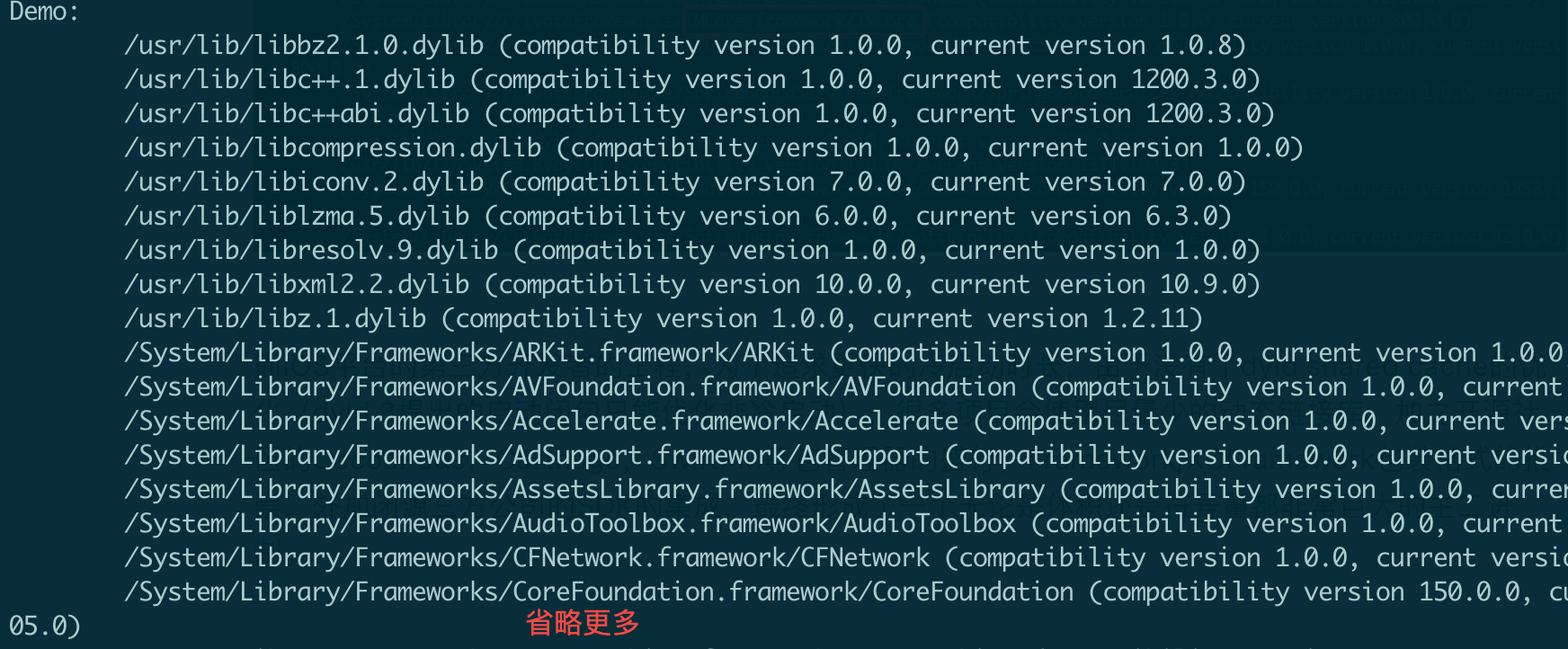
以公司内飞书应用的内测版为例子,在使用Debug,Onone模式编译,不剥离(Strip)任何符号情况下,可以看到其主二进制大小为1.1GB,动态链接库数量为105,但是仅包含Apple的系统库和Swift标准库。业务代码以静态链接库集成。
图3:公司飞书应用的动态链接库列表
上述这两种不同的工程结构,带来了非常显著的调试体验的差异,并且Apple公司近年来的Xcode Team和Debugger Team优化,并没有完全考虑部分第三方开发者常使用的,厚主二进制下的工程结构。
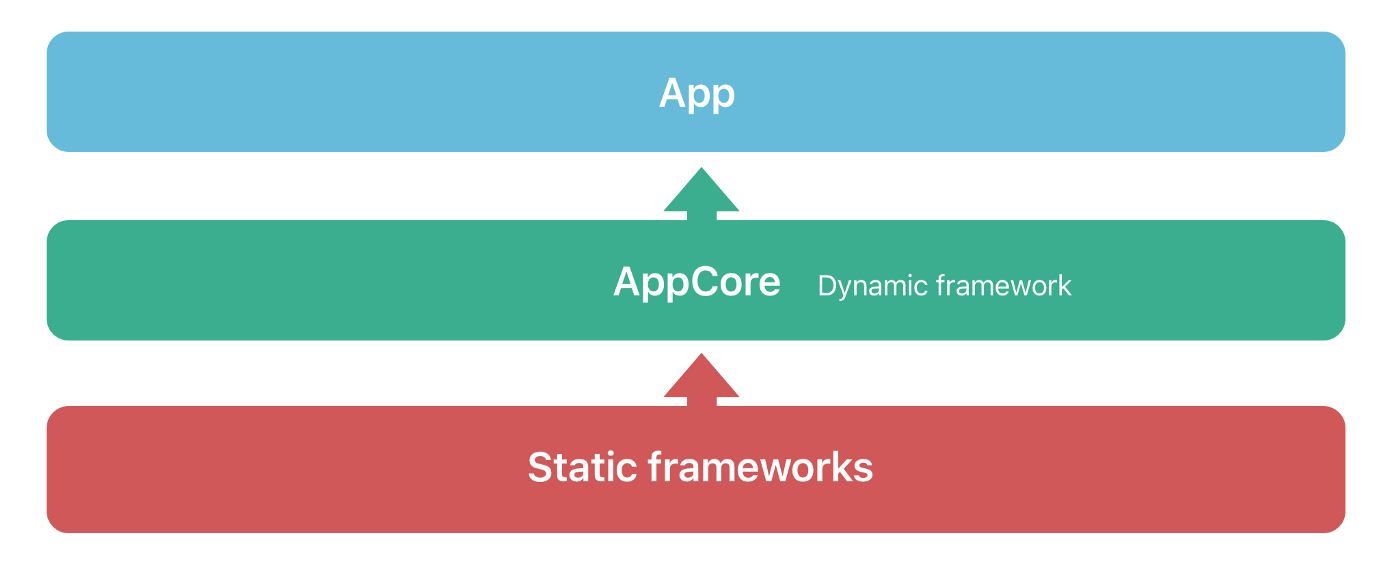
PS:理论上可以通过业务的工程结构的改造,在本地开发模式下,使用一个动态链接库包裹基础静态链接库的方式,减少主二进制大小(也会减少后续提到的DWARF搜索的耗时),但是大型项目推进工程结构的改造会是一个非常漫长的过程。
图4:一种减少主二进制大小的工程结构设计
解决方案:自定义LLDB工具链
经过调研,我们发现业界常见做法,无外乎这几种思路:
- 工程改造:缩减Swift Module/Search Path数量:可行,但是收益较低,且不可能无限制缩减
- 通过LLDB一些开关:可行,但是内部测试下依旧达不到理想的调试状态
我们致力于在字节跳动的移动端提供基础能力支持,因此提出了一套解决方案,不依赖业务工程结构的改造,而是从LLDB工具链上入手,提供定向的调试性能优化。
调研期间也确认到,借助自定义LLDB工具链,集成到Xcode IDE是完全可行的,包括iPhone模拟器、真机以及Mac应用。
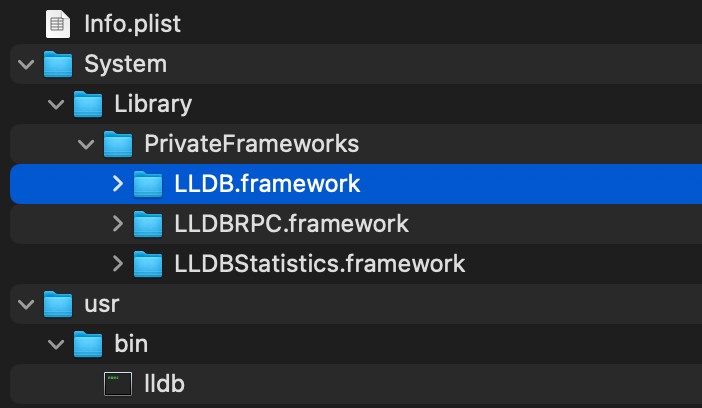
图5:自定义LLDB工具链的文件结构,系列后续文章会单独讲解,这里不展开
而LLVM/LLDB本身的工具链代码,在Apple的开源范畴之内(仓库地址:https://github.com/apple/llvm-project) 通过严格追踪跟进上游的发布历史,分支模型,能够尽可能地保证工具链的代码和功能的一致性。
实际收益
经过后文提到的一系列优化手段,以公司内大型项目飞书测试,编译器采取Swift 5.6,Xcode选择13.3为例,对比调试性能:
| 项目 | Xcode 13.3 | 自定义LLDB |
|---|---|---|
| v耗时 | 2分钟 | 40秒 |
| po耗时 | 1分钟 | 5秒 |
| p耗时 | 20秒 | 5秒 |
图6:切换自定义LLDB工具链

图7:调试优化演示,使用Xcode 13.3自定义LLDB,运行文中提到的耗时Demo(原po耗时约1分钟):
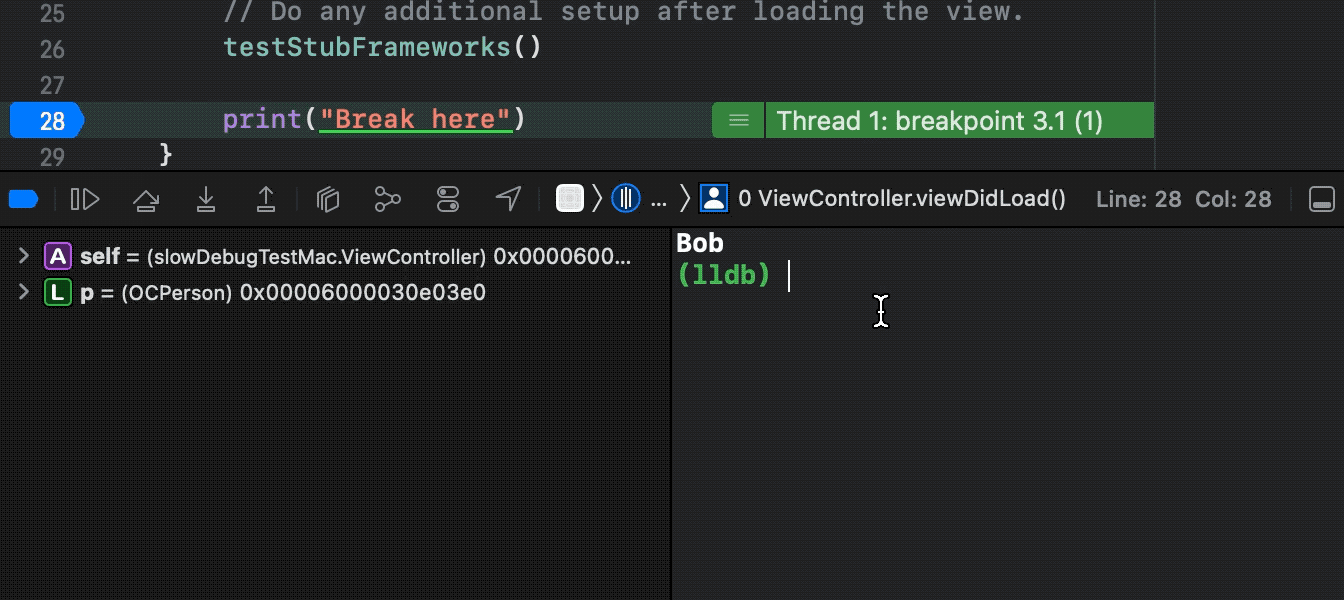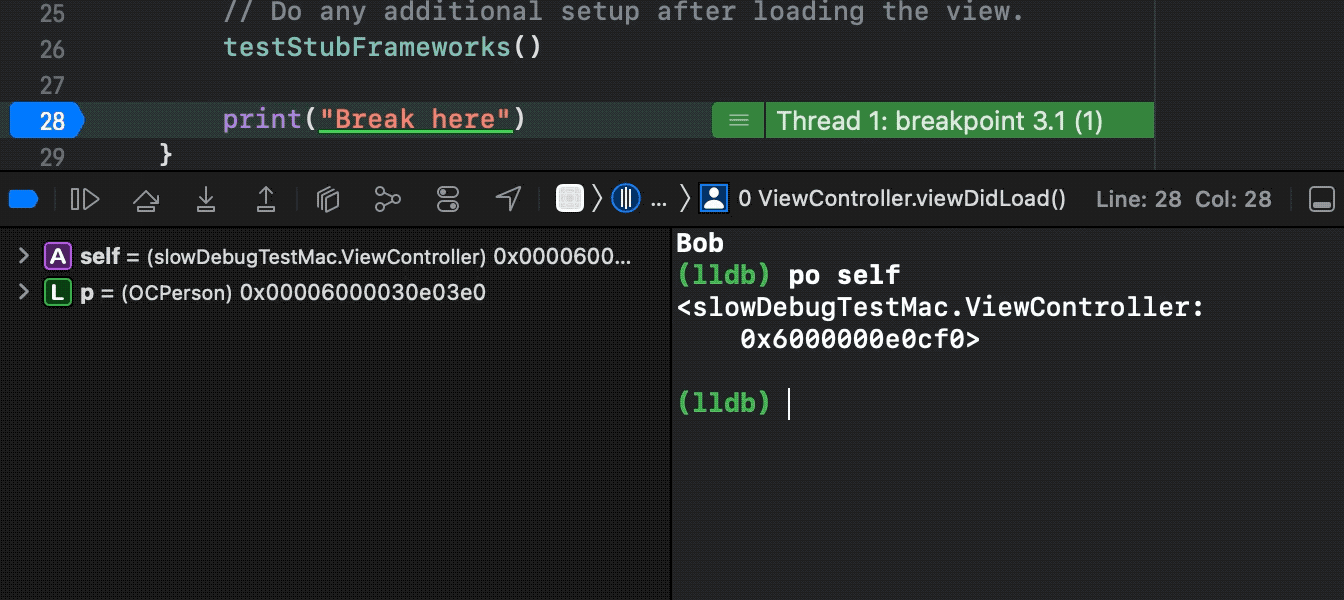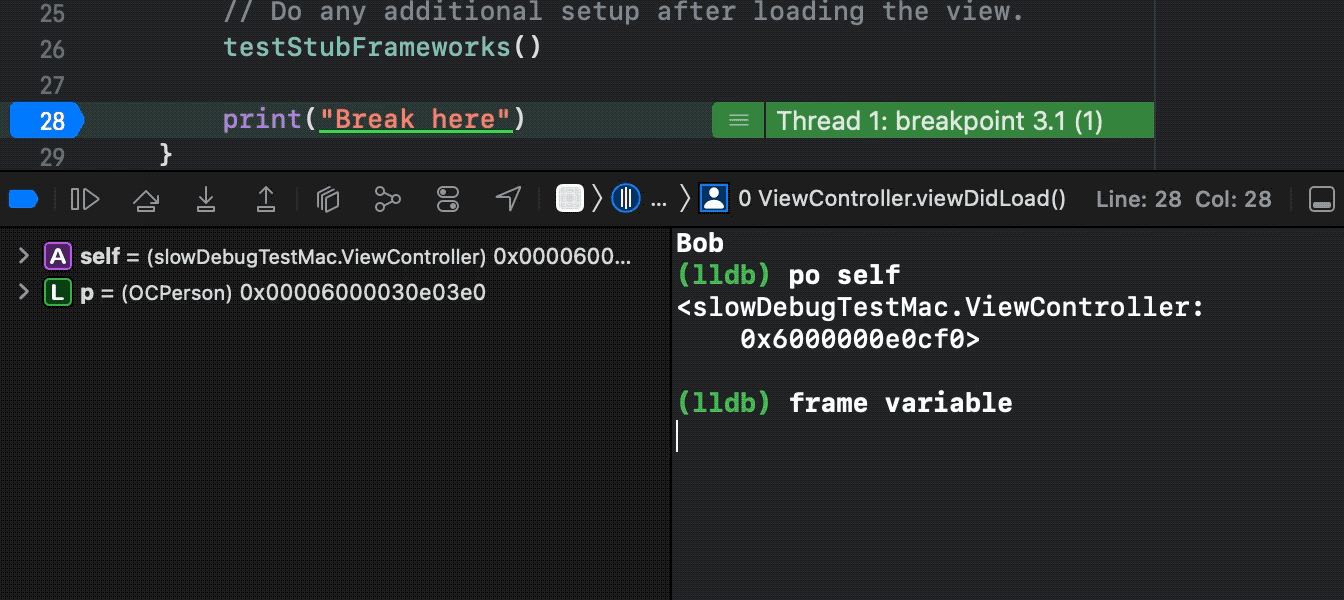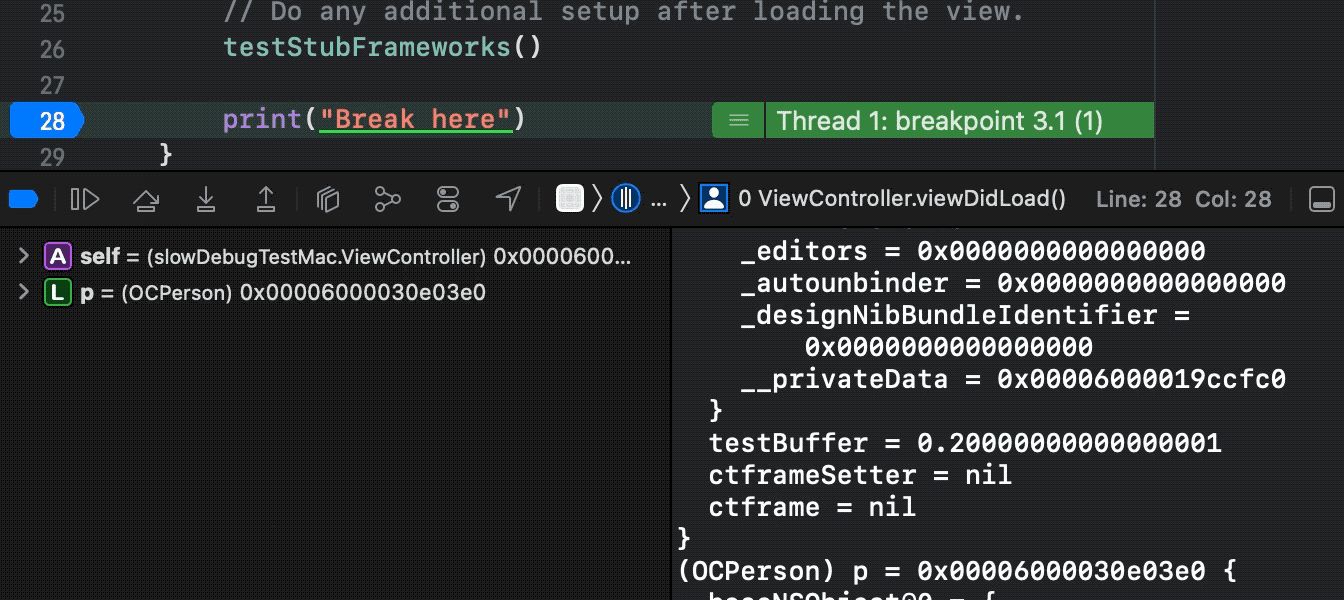
简述po/p/v的工作流程
在介绍我们自定义LLDB工具链的优化之前,首先来简述一下LLDB的核心调试场景的工作流程,方便后续理解优化的技术点。
我们一期的目的是主要优化核心的调试场景,包括最常见的“断点陷入到Xcode左侧变量区展示完毕”(v),“点击Show Description”(po),“勾选Show Types”(p)。这些对应LLDB原生的下面三个交互命令。
图8:LLDB的交互命令
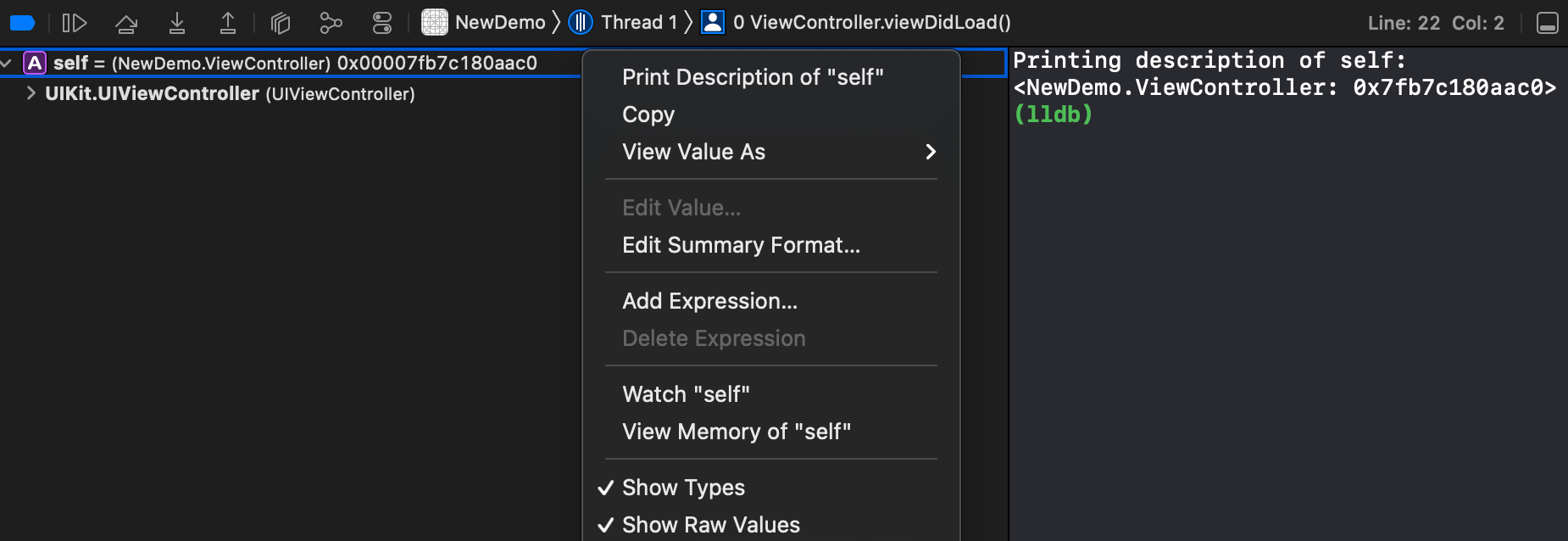
Apple在WWDC 2019-LLDB: Beyond “po”[2]中,进行了较为详细的介绍,这里我们进一步详细解释其部分工作流程,为后文的具体优化技术点提供参考。建议可以搭配视频一并学习。
po [expr]
po是命令expression --object-description -- [expr]的alias
图9:po的流程
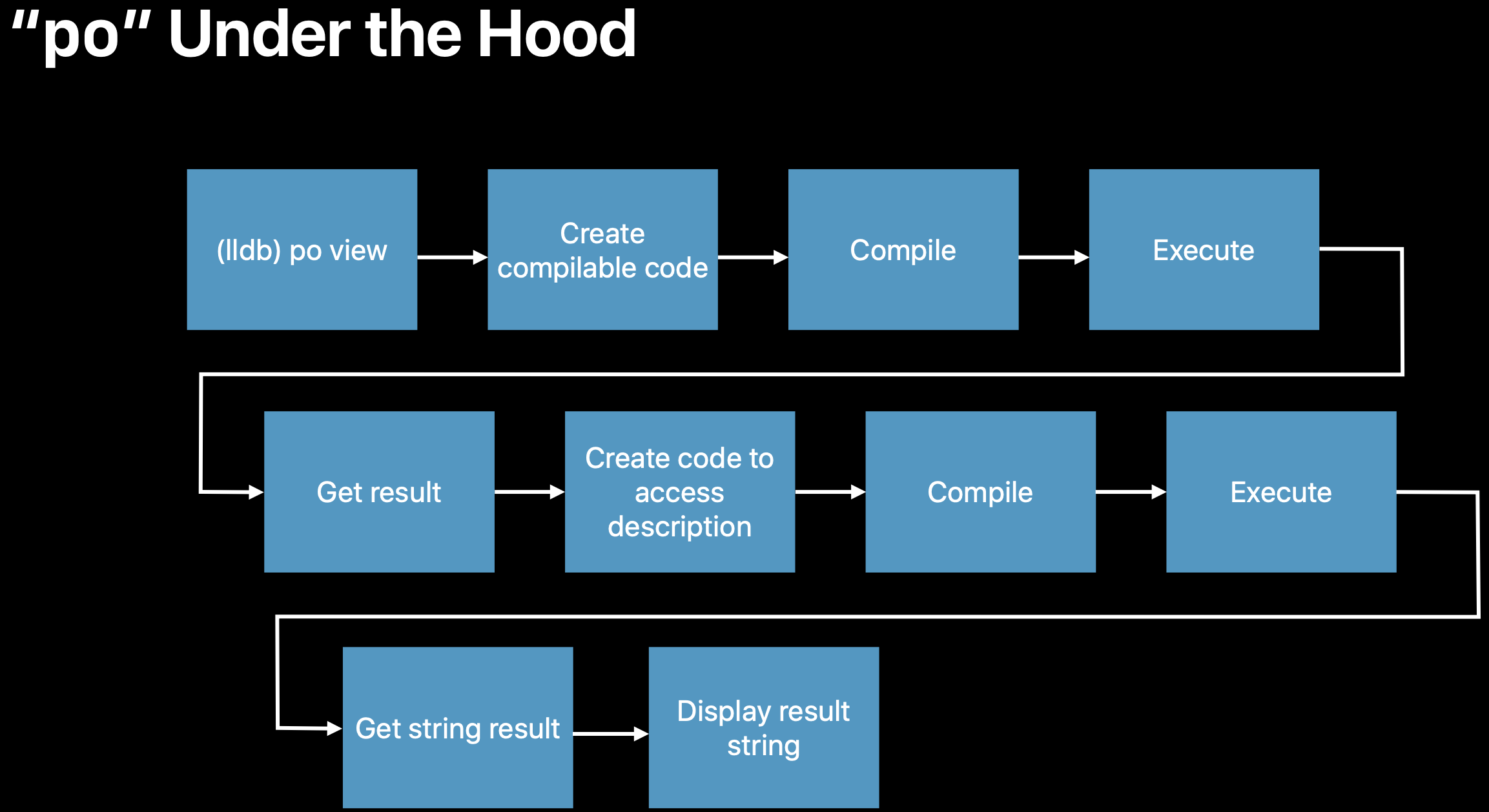
- 使用Swift编译器编译
result = expr得到IR
1 | // 精简版,实际较为复杂,源代码搜@LLDBDebuggerFunction关键字 |
执行IR代码
- 在支持JIT的平台上使用JIT,不支持则使用LLVM的IRInterpreter
获取执行结果
使用Swift编译器编译
result.description- 实际上LLDB调用的是Swift标准库的私有方法:_DebuggerSupport.stringForPrintObject[3]
执行IR代码
获取执行结果字符串
对得到的字符串进行格式化输出
p [expr]
p是命令expression -- [expr]的alias
图10:p的流程
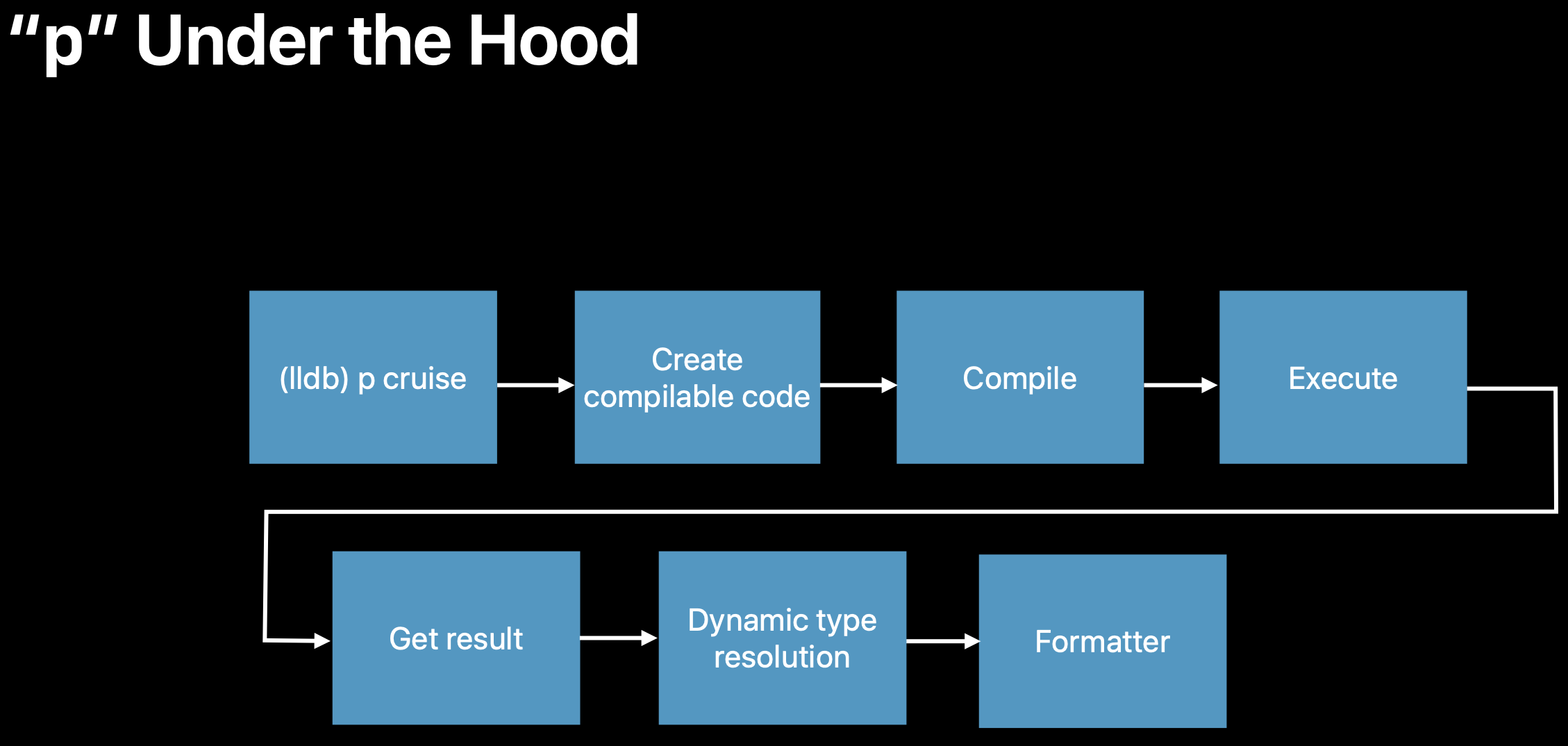
使用Swift编译器编译
result = expr得到IR执行IR代码
获取执行结果
对
result进行Dynamic Type Resolve- 利用Swift编译器提供的remoteAST,拥有源码的AST之后,会根据内存布局直接读取对象细节
- 也会利用Swift Reflection,即Mirror来进行读取,和remoteAST二选一
对得到的对象细节进行格式化输出
对比下来可以看到,po和p的最大不同点,在于表达式执行的结果,如何获取变量的描述这一点上。po会直接利用运行时的object description(支持CustomDebugStringConvertible[4]协议)拿到的字符串直接展示,并不真正了解对象细节。
图11:获取Object Description的实现细节(SwiftLanguageRuntime.cpp)
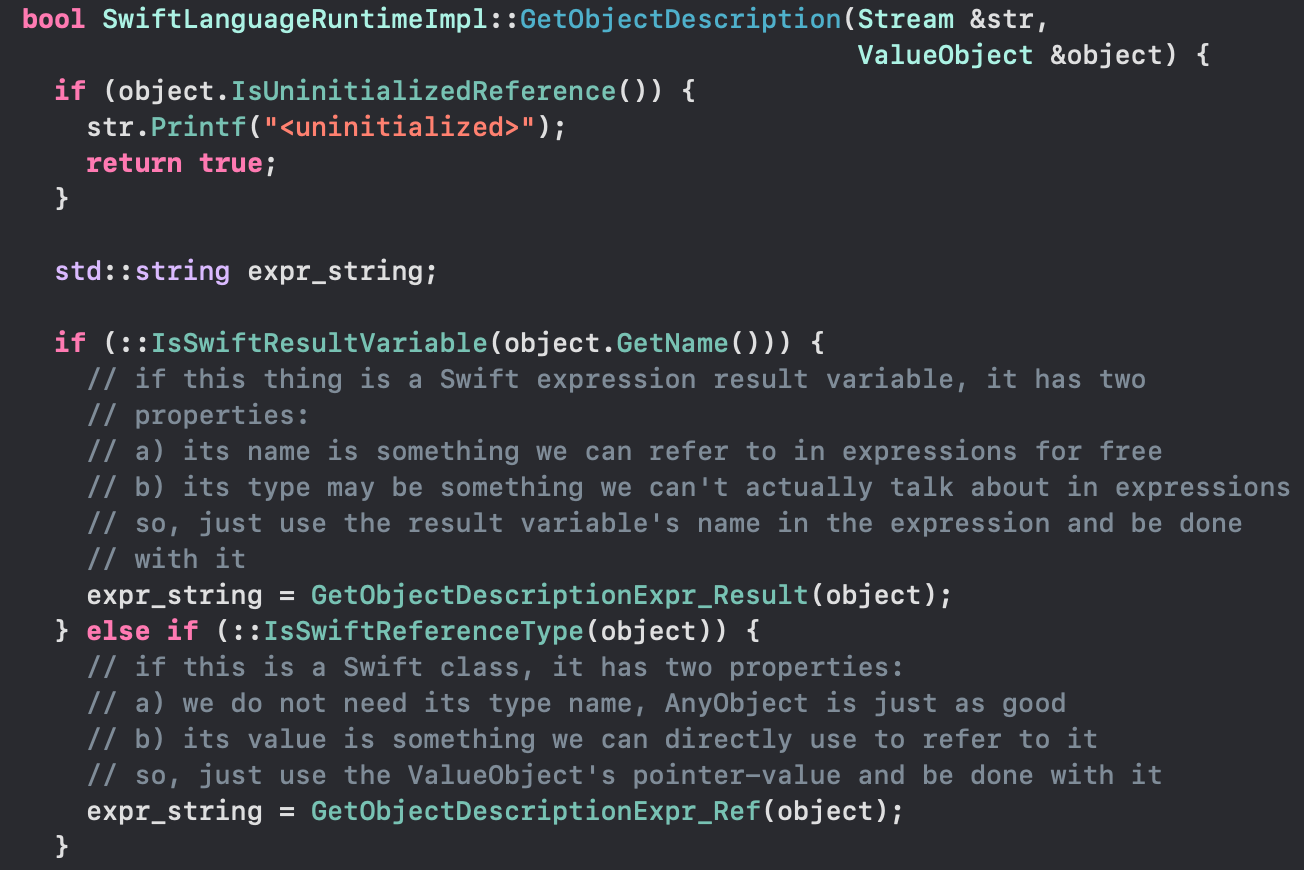
而p使用了Swift Runtime(Objc的话就是ISA,Method List那些,资料很多不赘述),拿到了对象细节(支持CustomReflectable[5]协议),进行按层遍历打印。不过值得注意的是,Swift Runtime依赖remoteAST(需要源码AST,即swiftmodule)或者Reflection(可能被Strip掉,并不一定有),意味着它强绑定了,编译时的Swift版本和调试时的LLDB的版本(牢记这一点)。并不像Objc那样有一个成熟稳定运行时,不依赖编译器也能动态得知任意的对象细节。
图12:Swift Dynamic Type Resolve的实现(SwiftLanguageRuntimeDynamicTypeResolution.cpp)
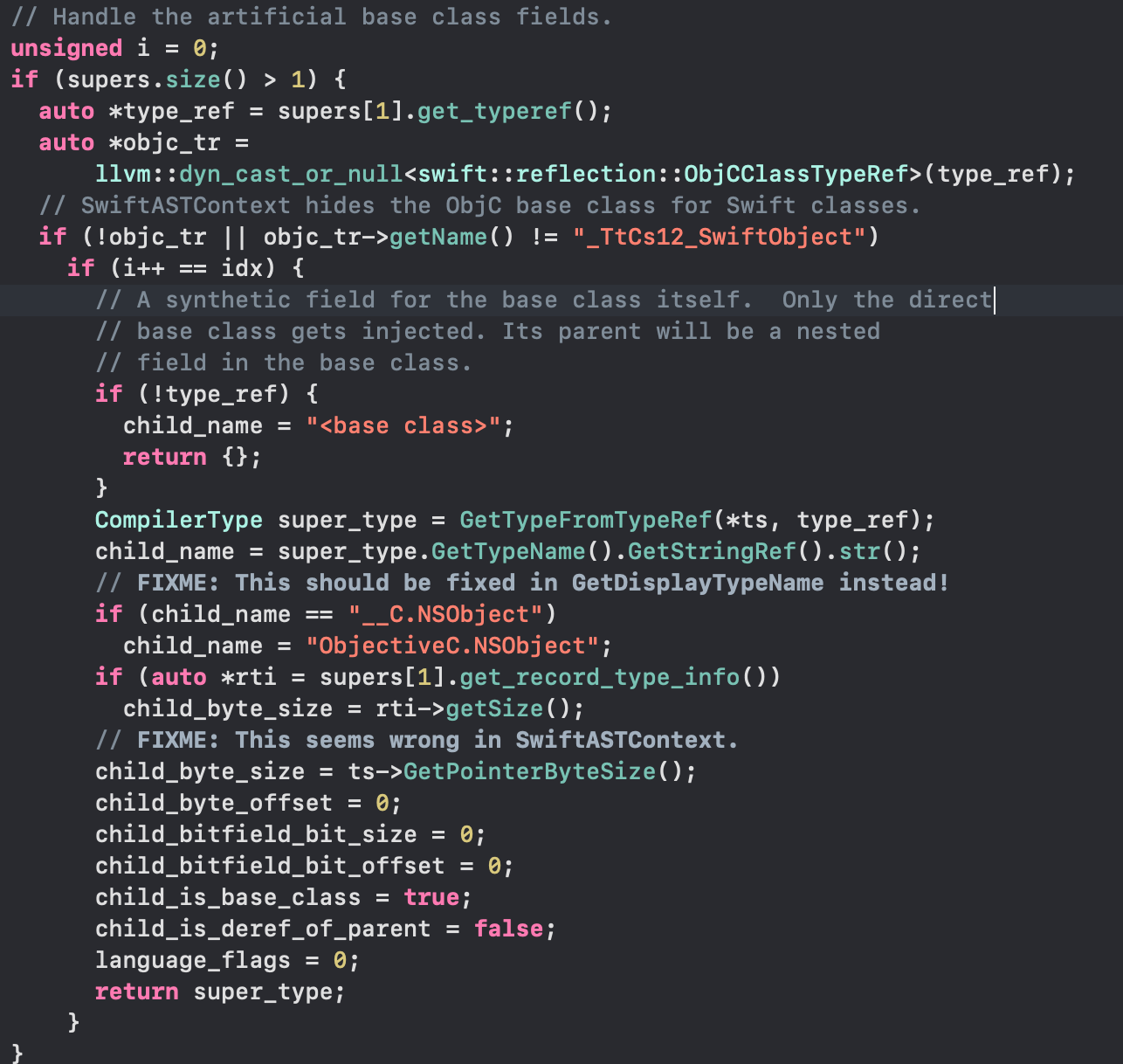
v [expr]
v是命令frame variable [expr]的alias
图13:v的流程
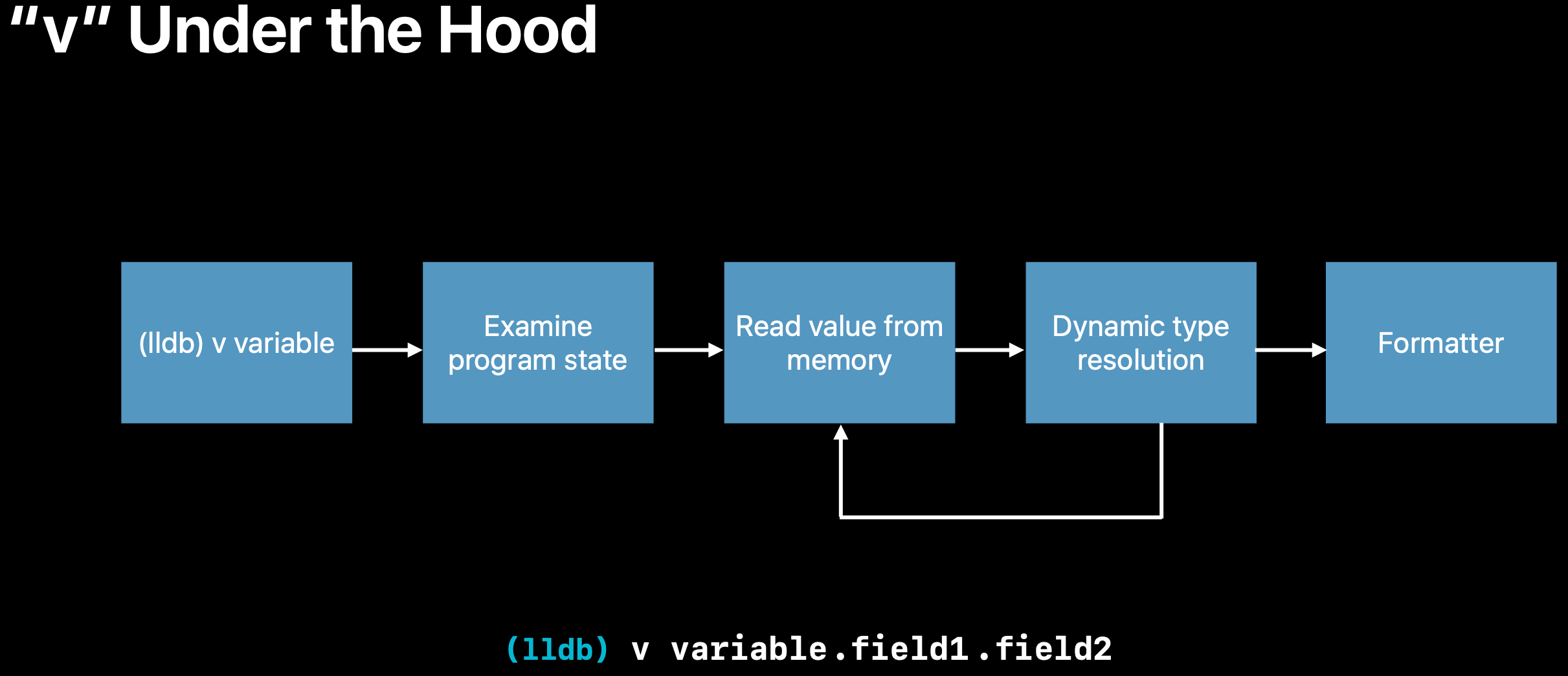
- 获取程序运行状态(寄存器/内存等)
- 递归开始
- 解释
expr的每一层访问(->或者.),得知当前变量的内存布局 - 对当前变量进行Dynamic Type Resolve
- 递归结束
- 对得到的对象细节格式化输出
v的特点在于全程没有注入任何代码到程序中,也就是它是理论无副作用的。它的expr只支持访问对象的表达式(->/.等),不支持函数调用,并不是真正的C++/C/OC/Swift语法。
优化v
下述所有说明基于发稿日的Swift 5.6(优化思路也适配Swift 5.5)说明优化方案,后续不排除Apple或者LLVM上游进行其他优化替代,具有一定时效性。
(暂时)关闭swift-typeref-system
- 关闭方式
1 | settings set symbols.use-swift-typeref-typesystem false |
- 开关说明
Prefer Swift Remote Mirrors over Remote AST
这里的remoteAST和Swift Mirror的概念,上文介绍过,不同方案会影响Swift的Dynamic Type Resolve的性能。
经过实测,关闭之后,内部项目的复杂场景下,断点陷入耗时从原本的2分20秒,缩减为1分钟。这部分开关,目前已经通过Xcode自定义的LLDBInit[6]文件,在多个项目中设置。
注:和Apple同事沟通后,swift-typeref-typesystem是团队20年提出的新方案,目前有一些已知的性能问题,但是对Swift变量和类型展示有更好的兼容性。关闭以后会导致诸如,typealias的变量在p/v时展示会有差异,比如TimeInterval(alias为__C.Double)等。待Apple后续优化之后,建议恢复开启状态。
修复静态链接库错误地使用dlopen(Fixed in Swift 5.7)
简述问题:LLDB在SwiftASTContext::LoadOneModule时假设所有framework包装格式都是动态链接库,忽略了静态链接库的可能性。
在调试测试工程中,我们追踪日志发现,LLDB会尝试使用dlopen去加载静态链接库(Static Framework),这是很不符合预期的一点,因为对一个静态链接库进行dlopen是必定失败的,如日志所示(使用下文提到的复现Demo):
1 | SwiftASTContextForExpressions::LoadOneModule() -- Couldn't import module AAStub: Failed to load linked library AAStub of module AAStub - errors: |
查看代码阅读发现,这里触发的时机是,LLDB在执行Swift变量Dynamic Type Resolve之前,因为需要激活remoteAST,需要加载源码对应的swiftmodule到内存中。
swiftmodule是编译器序列化的包含了AST的LLVM Bitcode[7]。除了AST之外,还有很多Metadata,如编译器版本,编译时刻的参数,Search Paths等(通过编译器参数-serialize-debugging-options记录)。另外,对Swift代码中出现的import语句,也会记录一条加载模块依赖。而主二进制在编译时会记录所有子模块的递归依赖。
LLDB在进行加载模块依赖时,会根据编译器得到的Search Paths,拼接上当前的Module Name,然后遍历进行dlopen。涉及较高的时间开销:N个Module,M个Search Path,复杂度O(NxM)(内部项目为400x1000数量级)。而在执行前。并未检测当前被加载的路径是否真正是一个动态链接库,最终产生了这个错误的开销。
- 修复方案
我们的修复方案一期是进行了一次File Signature判定,只对动态链接库进行dlopen,在内部工程测试(约总计1000个Framework Search Path,400个Module)情况下,一举可以减少大约1分钟的额外开销。
- 复现Demo
仓库地址:https://github.com/PRESIDENT810/slowDebugTest
这个Demo构造了100个Swift Static Framework,每个Module有100个编译单元,以此模拟复杂场景。
后文的一些测试数据优化,会反复提及这个Demo对比。
注:和Apple的同事沟通后,发现可以在上层进行来源区分:只有通过expression import UIKit这种用户交互输入的Module会进行dlopen检查,以支持调试期间注入外部动态库;其他情况统一不执行,因为这些模块的符号必然已经在当前被调试进程的内存中了。
Apple修复的PR:https://github.com/apple/llvm-project/pull/4077 预计在Swift 5.7上车
优化po/p
(暂时)关闭swift-dwarfimporter
- 关闭方式
1 | settings set symbols.use-swift-dwarfimporter false |
- 开关说明
1 | Reconstruct Clang module dependencies from DWARF when debugging Swift code |
这个开关的作用是,在开启情况下,Swift编译器遇到clang type(如C/C++/Objc)导入到Swift时,允许通过一个自定义代理实现,来从DWARF中读取类型信息,而不是借助编译器使用clang precompiled module[8],即pcm,以及ClangImporter导入桥接类型。
切换以后可能部分clang type的类型解析并不会很精确(比如Apple系统库的那种overlay framework,用原生Swift类型覆盖了同名C类型),但是能稍微加速解析速度,这是因为clang pcm和DWARF的解析实现差异。
禁用之后,对内部项目测试工程部分场景有正向提升约10秒,如果遇到问题建议保持默认的true。
优化External Module的查找路径逻辑
在混编工程中,Swift Module依赖一个C/OC的clang module是非常常见的事情。在这种情况下,LLDB需要同时使用编译器,加载到对应的clang module到内存中,用于进行C/OC Type到Swift Type的导入逻辑。
但是实际情况下,我们可能有一些Swift混编产物,是预二进制的产物,在非当前机器中进行的编译。这种情况下,对应编译器记录的的External Module的路径很可能是在当前机器找不到的。
LLDB的原始逻辑,会针对每一个可能的路径,分别由它的4种ObjectFile插件(为了支持不同的二进制格式)依次进行判断。每个ObjectFile插件会各自通过文件IO读取和解析Header。这是非常大的开销。
- 优化方案
我们内部采取的策略比较激进,除了直接利用fstat进行前置的判断(而不是分别交给4个ObjectFile插件总计判断4次)外,还针对Mac机器的路径进行了一些特殊路径匹配规则,这里举个例子:
比如说,Mac电脑的编译产物绝对路径,一定是以/Users/${whoami}开头,所以我们可以先尝试获取当前调试器进程的uname(非常快且LLDB进程周期内不会变化),如果不匹配,说明编译产物一定不是在当前设备进行上产出的,直接跳过。
图14:特殊匹配规则,直接避免文件IO判定存在与否
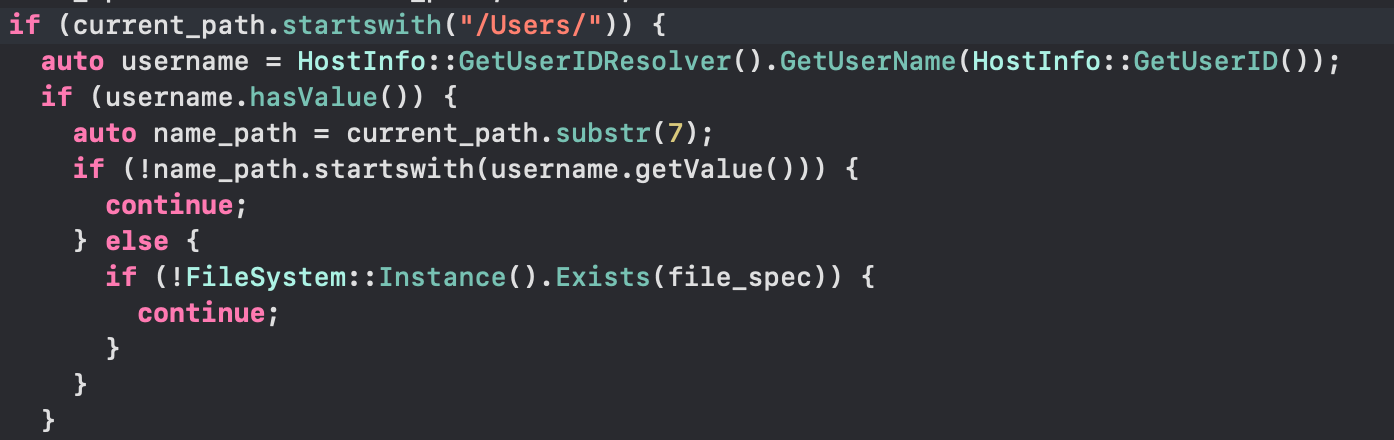
通过这一项优化,在内部项目测试下(1000多个External Module路径,其中800+无效路径),可以减少首次变量显示v耗时约30秒。
增加共享的symbols缓存
我们使用内部项目进行性能Profile时,发现Module::FindTypes和SymbolFile::FindTypes函数耗时调用占了主要的大头。这个函数的功能是通过DWARF(记录于Mach-O结构中),查找一个符号字符串是否包含在内。耗时主要是在需要进行一次性DWARF的解析,以及每次查找的section遍历。
LLDB本身是存在一个searched_symbol_files参数用来缓存,但是问题在于,这份缓存并不是存在于一个全局共享池中,而是在每个具体调用处的临时堆栈上。一旦调用方结束了调用,这份缓存会被直接丢弃。
图15:symbols缓存参数
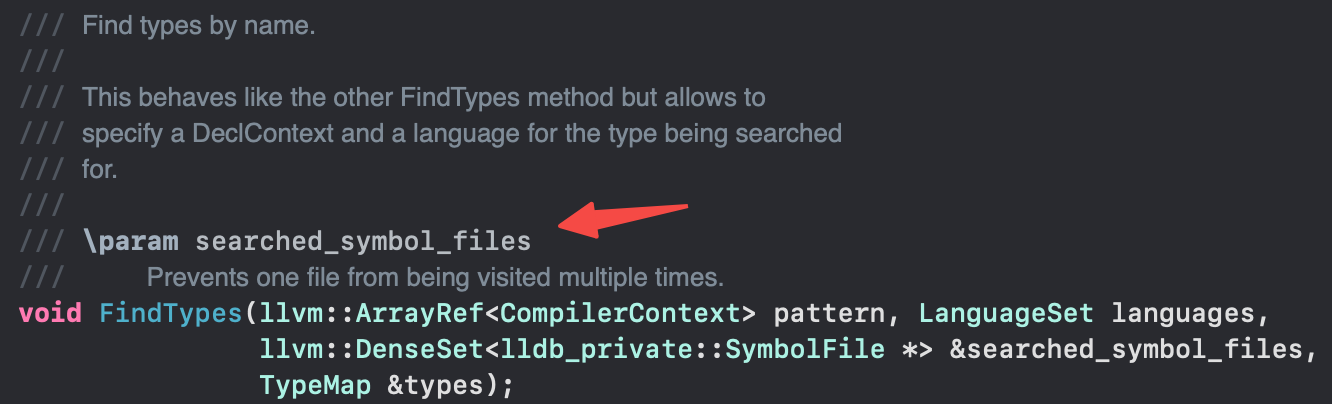
- 优化方案
我们在这里引入了一个共享的symbols缓存,保存了这份访问记录来避免多个不同调用方依然搜索到同一个符号,以空间换时间。实现方案比较简单。
内部工程实测,下来可以减少10-20秒的第一次访问开销,而每个symbol缓存占据字节约为8KB,一次调试周期约10万个符号占据800MB,对于Mac设备这种有虚拟内存的设备来说,内存压力不算很大。另外,也提供了关闭的开关。
优化不必要的同名symbols查找
另一项优化Module::FindTypes和SymbolFile::FindTypes函数开销的方案是,原始的这两个函数会返回所有匹配到的列表,原因在于C++/Rust/Swift等支持重载的语言,会使用naming mangle来区分同一个函数名的不同类型的变种。这些符号名称会以同样的demangled name,记录到DWARF中。
但是调用方可能会关心同名类型的具体的变种(甚至包括是const还是非const),甚至有很多地方只取了第一个符号,搜索全部的Symbol File其实是一种浪费(在Swift 5.6版本中找到累积约10处调用只取了第一个)
- 优化方案
我们对上述Module::FindTypes和SymbolFile::FindTypes函数,提供了一个新的参数match_callback,用于提前过滤所需要的具体类型。类似于很多语言标准库提供sort函数中的stop参数。这样,如果只需要第一个找到的符号就可以提前终止搜索,而需要全部符号列表不受影响。
图16:symbols查找筛选参数

内部项目测试这项优化以后,可以减少C++/C/OC类型导入到Swift类型这种场景下,约5-10秒的第一次查找耗时。
其他优化
定向优化Dynamic Type Resolve的一些特例
在实际项目测试中,我们发现,Dynamic Type Resolve是有一些特例可以进行针对性的shortcut优化,剔除无用开销的。这部分优化仅对特定代码场景有效,并不通用。这里仅列举部分思路
- 优化Core Foundation类型的Dynamic Type Resolve
Core Foundation类型(后文以CF类型指代),是Apple的诸多底层系统库的支撑。Objc的Founadtion的NS前缀的很多类型,也会Toll-Free Bridging[9]到CF类型上。而Swift也针对部分常用的CF类型支持了Briding。
CF类型的特点是,它内存布局类似Objc的Class ISA,但是又不是真正的Objc Class或者Swift imported Type,ISA固定是__NSCFType。
而目前LLDB遇到在Swift堆栈中出现的CF类型,依旧把它当作标准的clang type进行C++/C那一套解析,还会递归寻找父类ivar,比较费时。我们可以利用这一特点提前判定而跳过无用的父类查找。
图17:筛选CF类型
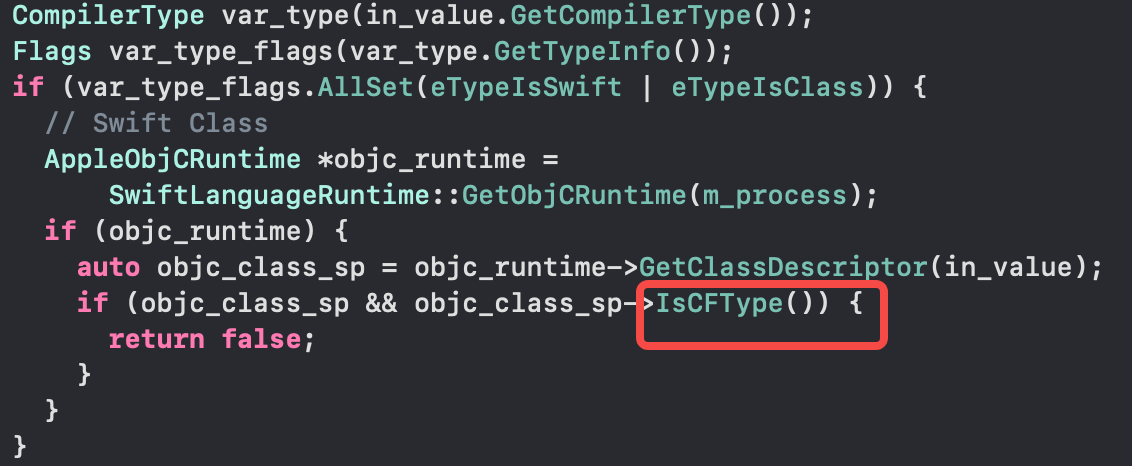
这一项优化在特定场景(如使用CoreText和CoreVideo库和Swift混编)下,可以优化10-20秒的每次Dynamic Type Resolve耗时。
接下来
我们在之后会有一系列的相关话题,包括:
- Xcode 13.3导致部分项目po提示Couldn’t realize type of self,有什么解决办法?
- 如何极速构建,分发自定义LLVM/LLDB工具链,来让用户无缝部署?
- 如何进行调试性能指标的监控和建设,包括Xcode原生的LLDB?
另外,这篇文章提到的非定制的优化和功能,均会向Apple或LLVM上游提交Patches,以回馈社区。
总结
这篇文章讲解了,大型Swift项目如何通过开关,以及自定义LLDB,优化Swift开发同学的调试速度,提高整体的研发效能。其中讲解了LLDB的部分工作流程,以及针对性优化的技术细节,以及实际效果。
我们的优化目标,不仅仅是服务于字节跳动移动端内部,更希望能推动业界的Swift和LLVM结合领域的相关发展,交流更多工具链方向的优化建设。
鸣谢
感谢飞书基础技术团队提供的一系列技术支持,以及最终业务试点提供的帮助推广。
感谢Apple同事Adrian Prantl在GitHub和邮件上进行的交流反馈,协助定位问题。
引用链接
- https://developer.apple.com/videos/play/wwdc2017/413/
- https://developer.apple.com/videos/play/wwdc2019/429/
- https://github.com/apple/swift/blob/release/5.6/stdlib/public/core/DebuggerSupport.swift#L242
- https://developer.apple.com/documentation/swift/customdebugstringconvertible
- https://developer.apple.com/documentation/swift/customreflectable
- https://lldb.llvm.org/man/lldb.html#configuration-files
- https://llvm.org/docs/BitCodeFormat.html
- https://clang.llvm.org/docs/Modules.html#id20
- https://developer.apple.com/library/archive/documentation/General/Conceptual/CocoaEncyclopedia/Toll-FreeBridgin/Toll-FreeBridgin.html